HAAM-RL with Ensemble Inference Method
1. Objective¶
This paper introduces a novel reinforcement learning approach, HAAM-RL, designed to optimize the color batching re-sequencing problem in automobile painting processes. Traditional heuristic algorithms face limitations in accurately reflecting real-world constraints and predicting logistics performance. The proposed methodology integrates tailored Markov Decision Process formulation, Potential-Based Reward Shaping, heuristic algorithm-based action masking (HAAM-RL), and ensemble inference methods to enhance performance. Through experimentation across 30 scenarios, HAAM-RL with ensemble inference achieves a significant 16.25% improvement over conventional heuristic algorithms, showcasing stable and consistent results. The study highlights the superior performance and generalization capabilities of the proposed approach in optimizing complex manufacturing processes and suggests future research directions such as alternative state representations and integrating model-based RL methods. It is also the first case where an external simulator is connected with our RL MLOps platform.
2. Methodology¶
The main skills I used in this project are : PyTorch, FlexSim, SAC, PPO, MLOps, FastAPI.
Three main contributions are presented in this paper.
- RL MDP
- Ensemble Method
- RL MLOps w. Flexsim
3. Contributions¶

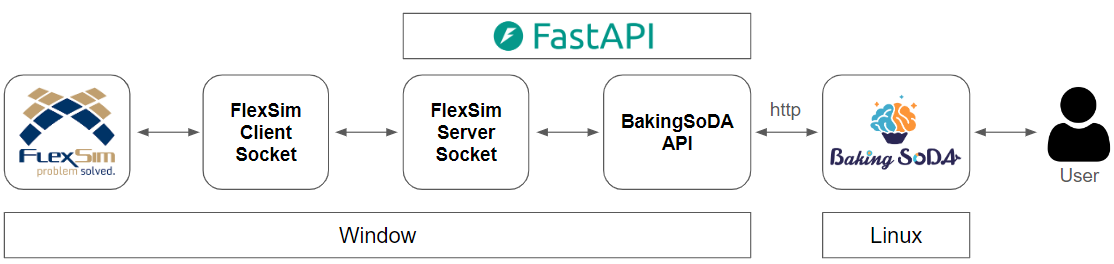
4. Experiment Results¶
Experiments show that our final algorithm, HAAM-RL
showed 16.25% improvement compared to the heuristic algorithm. The heuristic
algorithm
required
34 color changes for
100 vehicles, whereas HAAM-RL exhibited a lower number
of color changes at 29. As the number of vehicles and the
complexity of the environment increases, we expect HAAMRL to decrease the overall cost while
increasing efficiency
in productions.
Also, to verify the result’s stability and generalization potential, we also conducted experiments on 30 scenarios and analyzed their variance and standard deviation. The results showed a mean of 29.57, a variance of 6.530, and a standard deviation of 2.555. Furthermore, a 1 sample t-test was 0.05, which shows the minimal fluctuation in data.